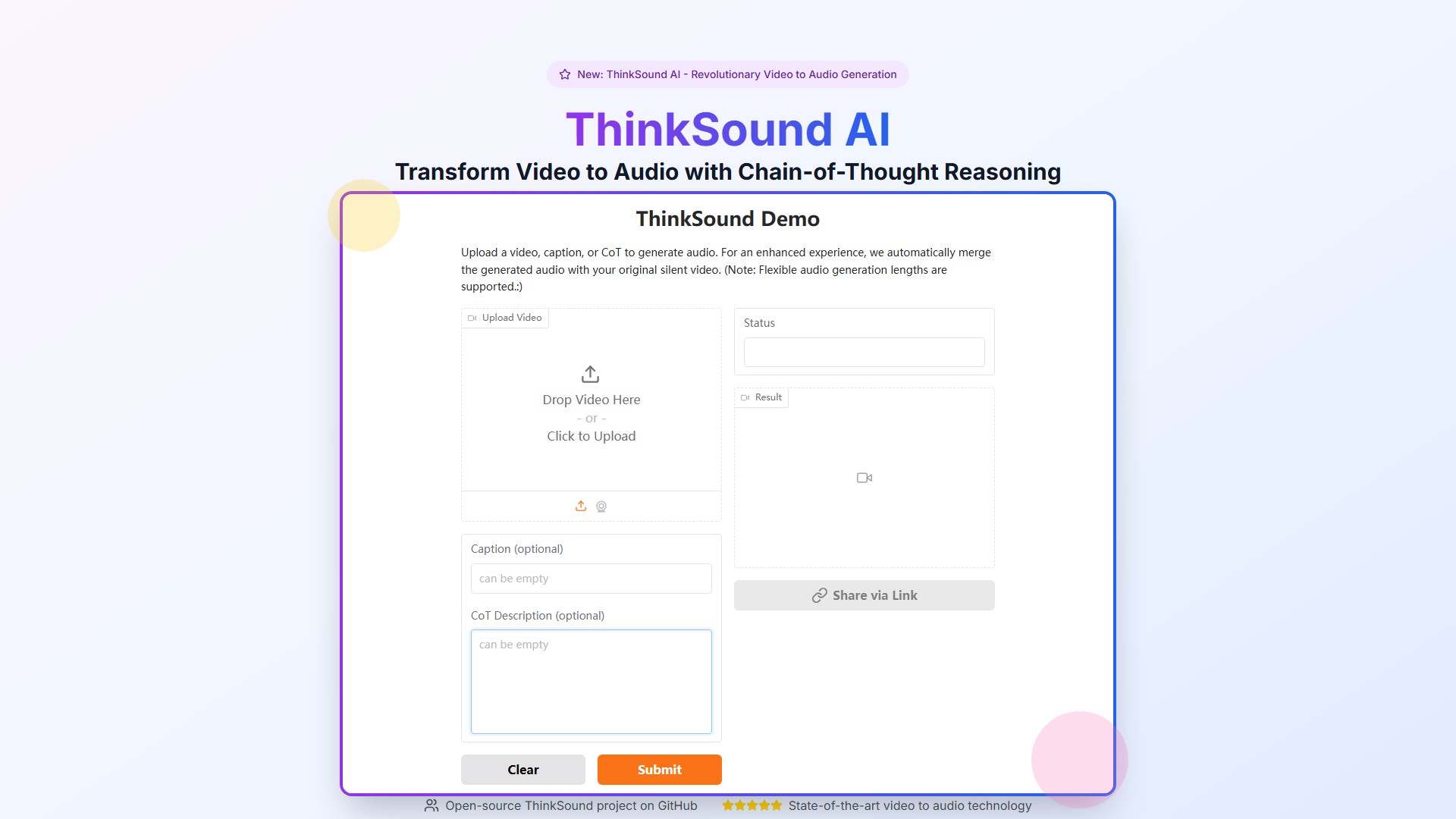
主要功能
- 视频转音频生成:使用Chain-of-Thought AI将任何视频转换为专业音景
- 三阶段生成过程:基础拟音生成、对象中心优化、自然语言编辑
- AudioCoT技术:结构化推理注释,实现语义连贯的视频转音频转换
- 交互式优化:通过简单的自然语言指令编辑和优化视频转音频输出
- 开源平台:在Hugging Face和GitHub上访问完整的视频转音频模型和数据集
使用流程
- 上传视频:ThinkSound AI使用多模态理解分析视觉内容
- Chain-of-Thought分析:将视频分解为音频元素,识别对象、动作和环境声音
- 三阶段音频生成:基础拟音声音、对象中心优化、自然语言编辑
- 交互式优化:使用自然语言指令精确控制每个音频元素
目标用户
- 研究人员:探索视频转音频技术的研究访问
- 开发者和创作者:需要API访问和高级功能的开发者访问
- 企业组织:需要定制化视频转音频解决方案的企业用户
核心优势
- 首个使用Chain-of-Thought推理的视频转音频框架
- 理解视觉上下文并生成语义连贯的音景
- 交互式优化功能,精确控制音频元素
- 开源项目,可访问完整模型和数据集
- 支持20多种语言,44.1kHz音频质量
定价方案
- Research Access(免费):访问研究、生成示例、AudioCoT数据集、GitHub仓库、社区支持(仅限研究使用)
- Developer Access(即将推出):API访问、高级Chain-of-Thought功能、自定义生成、优先处理、开发者支持、商业许可、模型微调、集成指南
- Enterprise(联系定制):自定义部署、高级定制、白标解决方案、专用实例、24/7支持、分析、团队协作、企业SLA
常见问题
- 工作原理:使用Chain-of-Thought推理通过三阶段转换视频到音频:基础拟音生成、对象中心优化、自然语言编辑
- 模型访问:开源项目,可在Hugging Face和GitHub访问模型、AudioCoT数据集和示例
- 独特性:首个使用Chain-of-Thought推理的视频转音频框架,理解视觉上下文并生成语义连贯音景
- API可用性:目前处于研究阶段,商业API即将推出
- 收录时间:2025-09-16
-
计价模式:
Contact for Pricing
Free
Paid
#音频编辑
#音乐
#文本转语音
#视频剪辑
#视频生成器
Contact for Pricing
Free
Paid
Website
Open Source